
U digitalnoj forenzici, brz pristup pouzdanim informacijama može biti ključan za rješavanje složenih istraga. Kako količina forenzičke literature, priručnika, izvještaja i obrazovnih materijala raste, pronalazak relevantnih informacija postaje sve teži i sporiji.
Kako bismo odgovorili na ovaj izazov, razvili smo interni prototip temeljen na Retrieval-Augmented Generation (RAG) arhitekturi koristeći LangChain, FAISS i open-source modele. Cilj je bio omogućiti forenzičarima i analitičarima postavljanje pitanja na prirodnom jeziku i dobivanje direktnih odgovora iz PDF dokumenata — bez potrebe za ručnim pretraživanjem ili listanjem stotina stranica.
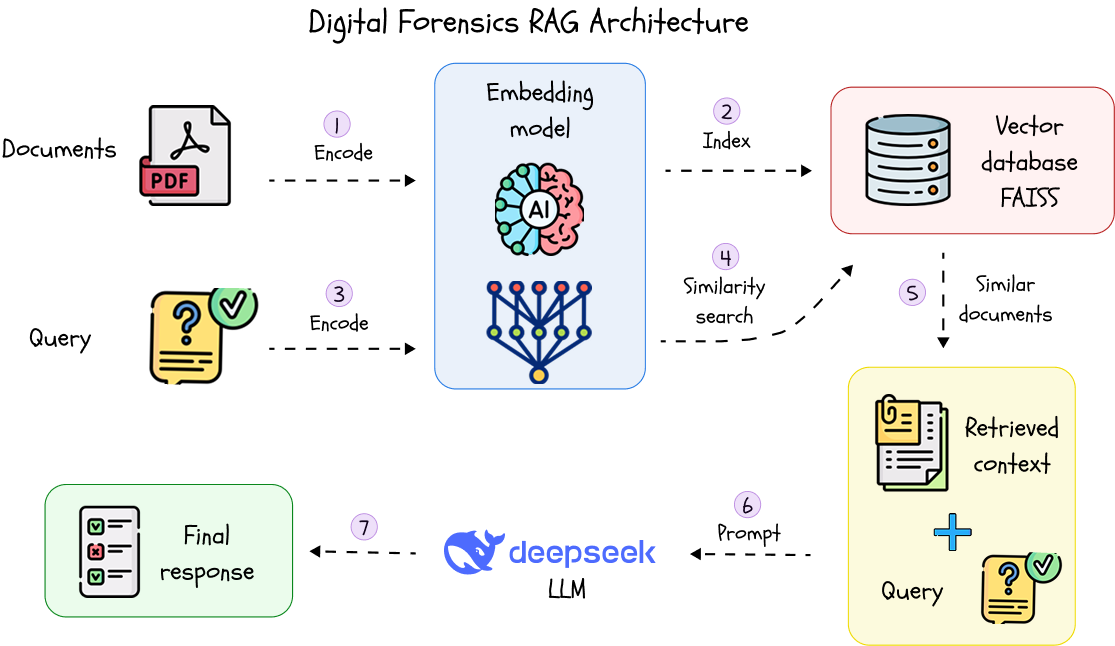
Implementirali smo modularni RAG sustav koji se sastoji od sljedećih komponenti:
• PDF Loader: Svi dokumenti iz mape /data automatski se skeniraju, a sadržaj se izdvaja pomoću semantičkog segmentiranja.
• Embeddings: Svaki segment teksta pretvara se u vektor pomoću Sentence-Transformer modela s Hugging Face platforme.
• FAISS Vektorska Baza: Vektori se indeksiraju i lokalno spremaju, omogućujući brzo i skalabilno pretraživanje po sličnosti.
• Pretraživač (Retriever): Kada korisnik postavi pitanje, pretraživač pronalazi najrelevantnije dijelove dokumenata koristeći Maximal Marginal Relevance (MMR).
• LLM (Ollama + DeepSeek): Lokalno pokrenut LLM interpretira kontekst i pitanje te generira smislen i referenciran odgovor.
• Streamlit Aplikacija: Jednostavno sučelje omogućuje svakom članu tima pretraživanje svih dokumenata — bez potrebe za programiranjem.
Izvorni kod za RAG asistenta dostupan je na GitHubu:
https://github.com/INsig2/Digital-Forensics-RAG
Zašto nam je ovo važno
• Brže pronalaženje dokaza: Uštedite sate koji bi inače bili potrošeni na prelistavanje priručnika ili arhiviranih izvještaja.
• Neovisno je o vrsti dokumenata: Radi sa svim kombinacijama forenzičkih materijala, knjiga ili internih PDF-ova.
• Lokalno izvođenje: Nijedan osjetljiv podatak ne napušta analitičarev uređaj.
• Skalabilnost: Indeks se automatski ažurira kad se dodaju novi PDF-ovi — znanje je uvijek aktualno.
Ovo rješenje pokazuje kako primjena modernih NLP tehnika — posebno Retrieval-Augmented Generation-a (RAG-a) — može donijeti stvarnu vrijednost za forenzičke stručnjake. Uz minimalne hardverske zahtjeve i potpuno open-source alate, izgradili smo pametnog asistenta koji timu omogućuje prirodnu, učinkovitu i skalabilnu interakciju s forenzičkim znanjem.
Jedna od ključnih prednosti našeg pristupa je korištenje lokalnog jezičnog modela (LLM).
Pokretanjem modela direktno na uređaju analitičara osiguravamo:
• Privatnost: Osjetljivi podaci nikada ne napuštaju sustav — ključno za digitalnu forenziku i slična regulirana područja.
• Nije potrebno spajanje na internet: Model radi i u izoliranim (air-gapped) ili offline okruženjima.
• Nema dodatnih troškova: Nema API poziva niti tokena — financijski isplativa alternativa komercijalnim rješenjima.
Iako je fokus na digitalnoj forenzici, ovaj RAG sustav može se lako prilagoditi bilo kojem području koje koristi velike zbirke tehničkih ili stručnih dokumenata — poput pravnog istraživanja, usklađenosti u zdravstvu, obuke u kibernetičkoj sigurnosti ili upravljanja internim politikama.
Autorica:
Marija Dragošević
Konzultantica digitalne forenzike
Resursi
[1] LangChain dokumentacija – službeni vodič za RAG, FAISS i retrievere: https://python.langchain.com/docs/introduction
[2] FAISS by Meta AI – učinkovit sustav za pretragu sličnosti: https://github.com/facebookresearch/faiss
[3] Hugging Face Sentence Transformers – za generiranje embeddinga: https://www.sbert.net
[4] Ollama – za lokalno pokretanje LLM-ova poput DeepSeek: https://ollama.com
[5] Streamlit – sučelje za razvoj demo aplikacije: https://streamlit.io

