
In digital forensics, quick access to trustworthy knowledge can be the key to solving complex investigations. As the volume of forensic literature, manuals, reports, and training material grows, finding relevant information efficiently becomes increasingly difficult.
To address this challenge, we developed an internal prototype based on a Retrieval-Augmented Generation (RAG) pipeline using LangChain, FAISS, and open-source language models. The goal was to allow forensic investigators and analysts to ask natural-language questions and get direct answers pulled from PDFs containing forensics knowledge — without needing to manually search or skim through hundreds of pages.
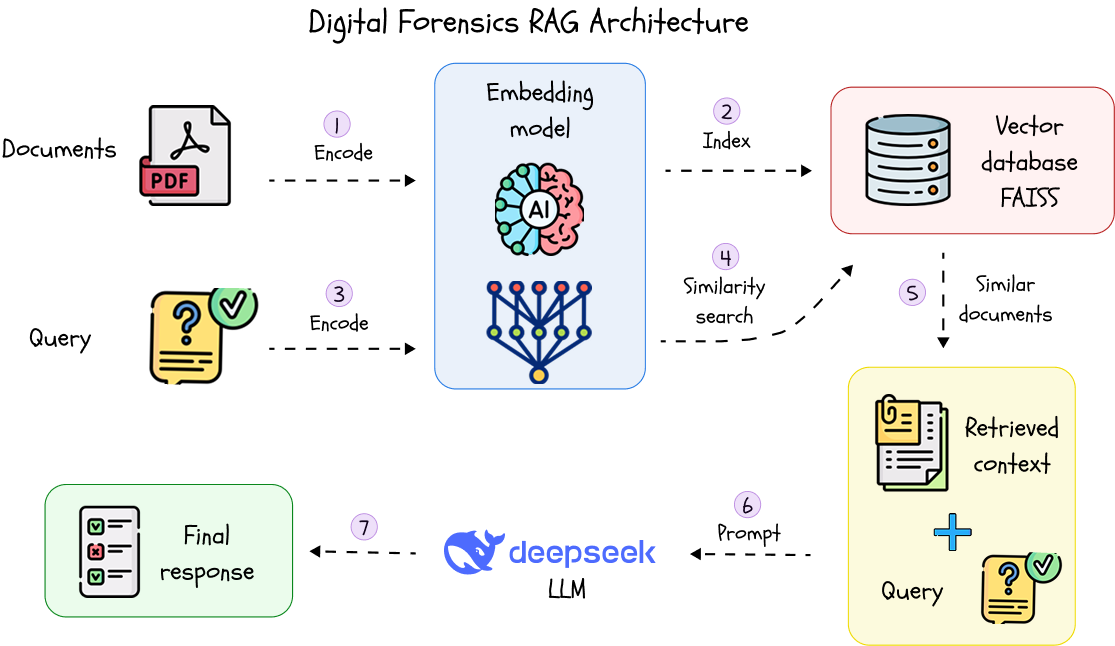
We implemented a modular RAG system with the following components:
• PDF Loader: All documents from a /data folder are automatically scanned, and content is extracted using semantic chunking.
• Embeddings: Each chunk is transformed into a vector using a Sentence-Transformer model from Hugging Face.
• FAISS Vector Store: Vectors are indexed and saved locally, enabling fast and scalable similarity search.
• Retriever: When a user submits a question, the retriever finds the most relevant document chunks using Maximal Marginal Relevance (MMR).
• LLM (Ollama + DeepSeek): A lightweight local LLM interprets both context and question to generate a meaningful, citation-backed answer.
• Streamlit App: A simple interface allows any team member to query across all uploaded documents instantly — no coding required.
The full source code for this RAG assistant is available on GitHub:
https://github.com/INsig2/Digital-Forensics-RAG
Why It Matters
• Faster Evidence Reference: Save hours otherwise spent skimming through training manuals or archived reports.
• Document-Agnostic: Works with any combination of forensic training materials, books, or internal PDFs.
• Runs Locally: No sensitive data ever leaves the analyst’s machine.
• Scalable: Index refreshes are handled dynamically as new PDFs are added — ensuring knowledge stays up-to-date.
This solution demonstrates how applying modern NLP techniques—especially Retrieval-Augmented Generation (RAG)—can create tangible value for forensic professionals. With minimal hardware and fully open-source tooling, we’ve built a smart assistant that empowers the team to interact with forensic knowledge in a natural, efficient, and highly scalable way.
One of the key advantages of our approach is the use of a local language model (LLM). Running the LLM entirely on the analyst’s machine ensures that:
• Sensitive data never leaves the system, which is essential in digital forensics and other regulated environments.
• No internet connection is required for inference, making it usable in air-gapped or offline scenarios.
• There are no API or token usage costs, offering a cost-effective alternative to commercial LLM APIs.
Beyond digital forensics, this RAG-based knowledge retrieval system can be adapted to any field that relies on large collections of technical or domain-specific documents—like legal research, healthcare compliance, cybersecurity training, or internal policy management.
Author:
Marija Dragošević
Digital Forensics Consultant
Resources
[1] LangChain Documentation – official docs that explain RAG pipelines, retrievers, FAISS, etc. https://python.langchain.com/docs/introduction
[2] FAISS by Meta AI – efficient similarity search engine used for indexing. https://github.com/facebookresearch/faiss
[3] Hugging Face Sentence Transformers – for generating embeddings. https://www.sbert.net
[4] Ollama – for running local LLMs like DeepSeek. https://ollama.com
[5] Streamlit – for the front-end of demo application. https://streamlit.io

